Long Road To Lexeme
| 2021-02-01 22:09:00 +0000 | Reading time:
16 mins
|
Long, long ago, in a galaxy far, far away.. Nah, I am just kidding. Not too far away, and not too long ago, but still, at certain moment in the past, I ended up in… Estonia.
And quite reasonably, I wanted to learn local language, to at least certain extent, - to be able to read
the inscriptions and explain myself whenever I need to find a bathroom. Now, Estonia provides truly
astonishing opportunities to learn the language: 100+ hours of free entry-level courses for everyone
newly arrived, and also a lot of deep, really extensive courses, for A2, B1, and B2 levels, where
number of participants is limited, but if you apply on time, everything is possible! For more information,
see Settle in Estonia webpage.
A quick word on Estonian language: it’s a member of Finno-Ugric language family, Balto-Finnic subgroup. It’s closest relative among living national languages is Finnish. Both these languages differ drastically from most other European languages, not only in terms of origin, but also in terms of “features”. They are “agglutinative”, which is to say, they tend to build quite a long “words”, which, when translated into other European languages, end up being the whole phrases, rather than single words.
Let’s look at an example: “kodudesse” would be translated as “into the houses”, “kodudeta” as “without the houses”, “kodudena” as “as the houses”, and so on. All these different ways to “incline” the original form “kodu” (the house), are called “the cases” (käänded in Estonian), and it is normally considered that Estonian language has 14 or 15 cases. Why this ambiguity? Well, I am not a linguist, but I would say it’s because long not all of these cases are actual cases, in a sense you would expect to have from Latin, Greek or Russian, but rather usual, traditional way of agglutinative languages to form phrases. But there’re some cases, that are real cases, in a sense that you cannot easily take a nominal form, attach a -ga or -ta to it’s end and call it a day. These are the notorious 3 basic forms, as they are taught to beginners, although actually they are cases: nominative, genitive and partitive.
And here’s where the whole fun begins: quite often, you cannot anyhow deduce those forms, based on the “nominative” one, which is, in most cases, the only one, given in a dictionary. Compare, for example:
| Nominative | Genitive | Partitive | Translation |
|---|---|---|---|
| iga | ea | iga | age |
| vesi | vee | vett | water |
| lugu | loo | lugu | (hi)story |
| lumi | lume | lund | snow |
| roog | roa | rooga | dish |
| idu | eo | idu | embryo |
and so on.. To make matters worse, most of the cased (inclined) forms are formed by taking the so-called second form (i.e. genitive), and attaching case-specific suffix to the end of it. But the words in dictionary are only given in nominative (for the most part, at least). So, until you’ve built up an intuition concerning “how do I form genitive/partitive for this word”, you will have not only many problems with speaking/writing properly, but also, in many cases, you won’t be able to find a word in a dictionary, plain and simple!!
And of course, in the majority of cases the word occurs in a phrase in inclined form, so this is quite a setback, when you are only starting to learn the language!
So.. this realization has dawned on me quite early. And I started to look around for some tutorials, or tools, or apps, that would facilitate solving this exact problem: finding a “nominal” form for a word, that I came across in “inclined” form. By the way, I’ve discovered quite useful tool, called Cooljugator, which helps to solve similar problem, but for verbs. But for the nouns… To be clear, online dictionaries, provided by EKI (Eesti Keele Instituut = Institute of Estonian Language), are quite sophisticated and they do provide basically all necessary forms, but back in the day they did not let you do the lookup based on inclined form.
And one day, I came across this. This is a software, written in Delphi 2 (!!), that you can download, and it gives you a GUI like this:
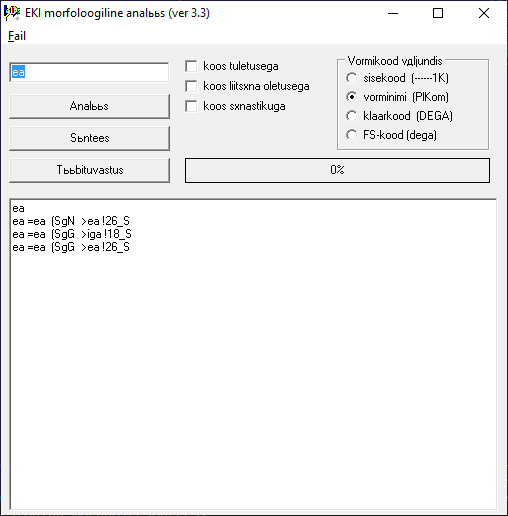
This tool has three major modes: analysis, synthesis and .. type formation (? I guess). “Analysis” mode can be used when you have an inclined form, and want to understand which nominal forms (or, “words”) this form could belong to. So, in the screenshot above, a form “ea” is analyzed to be one of the three possibilities: a nominative and a genitive forms of a word “ea” (I am not quite sure of the meaning), and a genitive of a word “iga” (age).
And a “synthesis” tool let’s you generate all the forms for any (almost, at least) Estonian word. Quite a win! or so I
thought. It had some drawbacks to it, though - first, it’a Windows GUI application, written ages ago, and apparently
compiled for Cp1257 codepage, whereas my desktop PC uses Cp1251 for non-Unicode apps, and I need it to stay this way. So,
using this for Estonian words, which quite often contain non-ASCII characters, such as ü, õ, ä, and some others, would
not be very practical. Second, I wanted something more usable, maybe a web-based tool, and for that one would need an
API, and that would be non-practical via GUI (although, feasible, I guess, with some kind of
AutoIt automation (oh, those days…).
Ok, so my first problem to address would be to learn to use those Delphi 2 DLLs from some CLI app. I have been curious about Rust for quite some time already, so I thought - why not? Sounds like a perfect match. And… after quite some trial and error… it worked! Now I could do stuff like this:
C:\Develop\Rust\rust-est\target\i686-pc-windows-msvc\debug>rust-est.exe analyze ühte
Analyze for "ühte":
ühte =ühte (ID >ühte !41_D
ühte =ühte (SgG >ühe !06_S
ühte =ühte (SgP >üks !22_NP
ühte =ühte (SgAdt >üks !22_NP
ühte =ühte (PlP >üht !22_S
ühte =ühte (IndPrPs_ >ühtema !27_V
ühte =ühte (ImpPrSg2 >ühtema !27_V
or this:
C:\Develop\Rust\rust-est\target\i686-pc-windows-msvc\debug>rust-est.exe synthesize uht
S, 22, 1, 1, SgN, üht (3)
S, 22, 1, 1, SgG, ühi (3)
S, 22, 1, 1, SgP, ühti (4)
S, 22, 1, 1, SgAdt, ühti (4)
S, 22, 1, 1, SgIll, ühisse (3)
S, 22, 1, 1, SgIn, ühis (3)
S, 22, 1, 1, SgEl, ühist (3)
S, 22, 1, 1, SgAll, ühile (3)
S, 22, 1, 1, SgAd, ühil (3)
S, 22, 1, 1, SgAbl, ühilt (3)
S, 22, 1, 1, SgTr, ühiks (3)
S, 22, 1, 1, SgTer, ühini (3)
S, 22, 1, 1, SgEs, ühina (3)
S, 22, 1, 1, SgAb, ühita (3)
S, 22, 1, 1, SgKom, ühiga (3)
S, 22, 1, 1, PlN, ühid (3)
S, 22, 1, 1, PlG, ühtide (4)
S, 22, 1, 2, PlP, ühtisid (4) ~ ühte (4)
S, 22, 1, 2, PlIll, ühtidesse (4) ~ ühesse (3)
S, 22, 1, 2, PlIn, ühtides (4) ~ ühes (3)
S, 22, 1, 2, PlEl, ühtidest (4) ~ ühest (3)
S, 22, 1, 2, PlAll, ühtidele (4) ~ ühele (3)
S, 22, 1, 2, PlAd, ühtidel (4) ~ ühel (3)
S, 22, 1, 2, PlAbl, ühtidelt (4) ~ ühelt (3)
S, 22, 1, 2, PlTr, ühtideks (4) ~ üheks (3)
S, 22, 1, 1, PlTer, ühtideni (4)
S, 22, 1, 1, PlEs, ühtidena (4)
S, 22, 1, 1, PlAb, ühtideta (4)
S, 22, 1, 1, PlKom, ühtidega (4)
S, 22, 1, 1, Rpl, ühe (3)
By the way, my biggest PITA with this project was not so much Rust language itself, as it was trying to figure out proper way to execute FFI calls against that Delphi calling convention. Here’s my struggle summarized: ACCESS_VIOLATION after returning from Rust fn that had FFI call to dll (BTW, huge kudos to Yandros! I was nearly despaired already, but this guy saved me!)
This implementation took me roughly 5 months … I know! I was often in despair or just had not enough energy to work on this project. Rust implementation started on Mar. 18, 2019, and by Aug. 5th it was mostly over, but mostly, it was maybe 10-15 evenings and couple of weekend days
So, there you have it - now I had a solid, Unicode-friendly, CLI app, that I could easily turn into a web-server, exposing HTTP API that could be consumed from anywhere.. hopefully. But there still was a catch: internally, it was still relying on those Windows DLLs, that would basically mean that I would need a Windows VM to host this on.. and as I could expect, that would be quite a bummer. So, I thought - what if I could pre-calculate all the forms, for all (or most) of the known words in Estonian, store them in a database, and then expose this database via API? By this time I wanted to create a simple web app where you could paste any form and it would give you all possible “nominal forms”, i.e. words you could then lookup in a dictionary. So I started to sniff around for a source of all Estonian words, and, of course, on the eki.ee it was found, in a form of a huge XML file, containing “Estonian-Russian dictionary” (EVS in Estonian). I won’t give a link here, but curious readers will sure find their way :)
Parsing the dictionary and adding processing logic to my Rust program, took me another 9 months - by May 2020 it was complete (but basically, that project was just abandoned for most of this time). So, by now I was able to:
- read the entry from dictionary XML (article code, basic form, parts of speech);
- feed it into the “synthesize” DLL, thus obtaining all possible paradigms (a “paradigm” is a collection of inclined forms for certain words);
- write all of those into a set of CSV files;
- repeat for the whole dictionary.
And why this “CSV” thing when I could just put the data straight into the database? Well, by this time I was already psychologically exhausted by this project and just wanted to bloody finish it. And it was clear that with Rust I won’t be able to do it quickly (looking at you, learning curve!).
So, I decided to quickly hack the “CSV solution” and then write the parsing in something I know well enough - Java, a.k.a “the pillar stone of contemporary enterprise”. Another factor that made me a little less enthusiastic about this project was the fact that by this time, May 2020, Sõnaveeb was launched. And that was essentially what I wanted to make, but on steroids: not only it lets you search for any form of the word, it provides instant translations (in most cases, at least), complete validated paradigms, usage examples, frequency information and what not. This is an official EKI development, the code of which, by the way, is open source!. Rejoice, “language X coding” geeks!
As the one who learns Estonian, I couldn’t be more happy. As a developer, my heart was broken (haha!). “What if all my labors were in vain?” I was asking myself, pedaling through the Estonian amazing wilderness with all it’s swamps and woods. (During the summer 2020, I finished, piece-meal, bigger half of an Oandu-Ikla trail, mostly on bike, and am strongly inclined to finish it for good this summer!)
By that time, I’ve already had read this article about Lexicographical Data on Wikidata. I’ve even discovered excellent lexeme-forms tool by Lucas Werkmeister, and even contributed “verbs” page for it, however, this contribution has never been merged, but frankly, who would want to be putting 47(!) forms for verb manually?
So, I thought, what if instead of doing something for myself, I would do something for the community? I started reading more on the topic, and quickly settled on my new direction: populate Estonian lexemes on Wikidata. With that in mind, I started writing this Java-based application.
This process, naturally, did not happen, overnight. First thing I needed to check the current state of affairs with Estonian Lexemes on Wikidata. Here’s how you can do it, too: navigate to Wikidata Query Service and run this query:
SELECT ?lexeme ?lemma WHERE {
?lexeme dct:language wd:Q9072;
wikibase:lemma ?lemma.
}
(wd:Q9072 is a Wikidata ID for an “Estonian language” item).
You should get something like this:
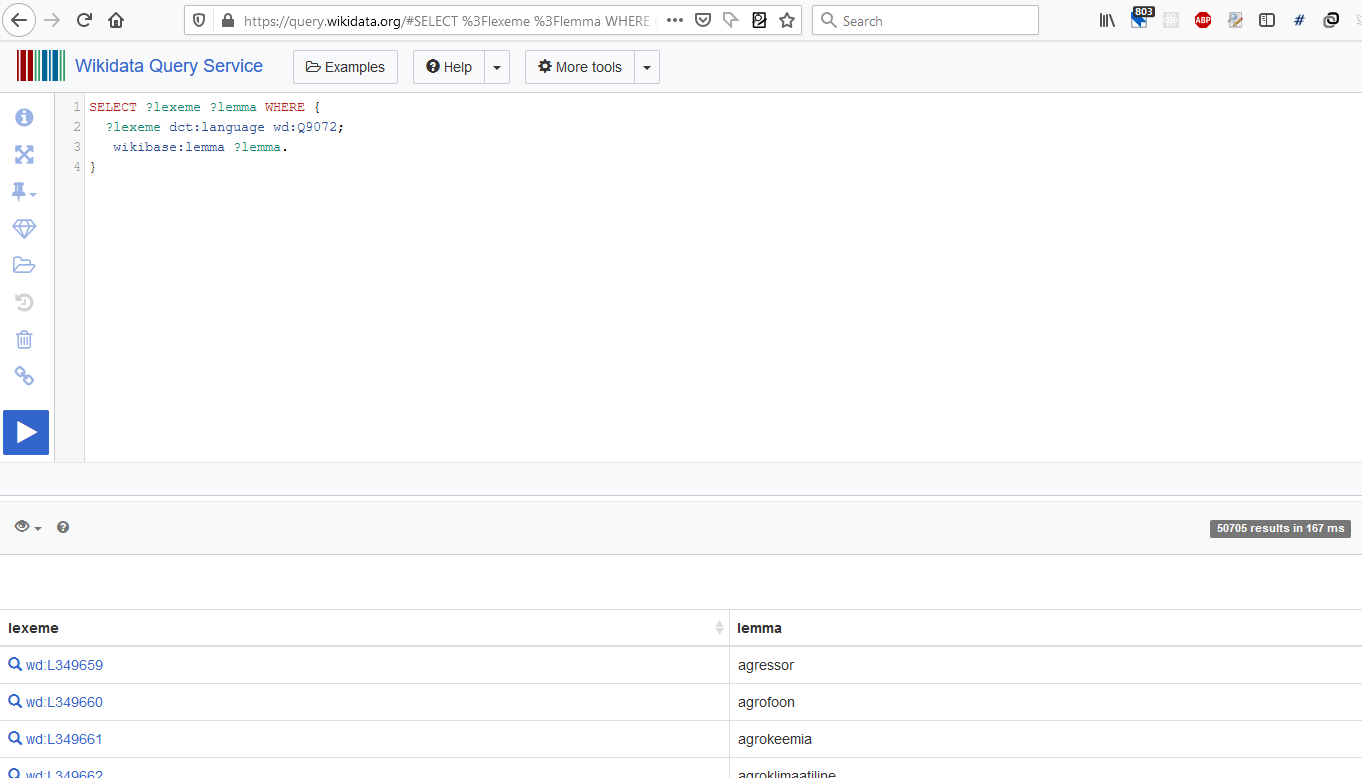
Currently, there’s more than 50K lexemes defined for Estonian, but before I’ve started, there were only.. 33! I ran the ranking query on Oct. 10th:
SELECT ?languageLabel ?lexemeCount {
{ SELECT ?language (COUNT (?lexeme) as ?lexemeCount) { ?lexeme dct:language ?language . } GROUP BY ?language }
SERVICE wikibase:label { bd:serviceParam wikibase:language "en". }
}
ORDER BY DESC(?lexemeCount)
and Estonian language rank was 68th, right between Swahili and Middle French (and exactly the same as Proto-Indo-European).
By the way, all the SPARQL (which is a query language, used to query Wikidata) queries I used for the project, you can find under this gist.
Having confirmed, that Estonian Lexeme are indeed not exactly over-represented on Wikidata, I started figuring out
approach how to automate the upload process. First, I needed to collect information about existing items, to re-use them as much as possible.
I needed to also count information on defined forms, so as to avoid writing to items that already have some forms defined.
For these aspects, I settled on using SPARQL, and for running queries from Java I’ve used Eclipse RDF4j
and it seems as thought just one artifact was sufficient: rdf4j-repository-sparql. (By the way, making it work with
Spring Boot suddenly brought a lot of fun).
And finally, to upload the lexemes, I needed something else, and luckily, Wikidata has an official Java client: Wikidata Toolkit. Not so luckily, it currently can not write or update Lexemes at all. So, to dance this around, I’ve created quite an ugly hack which I basically tested against test Wikidata until I was quite confident that it’s working OK.
Next, it was time to create a bot. “Bot account” is a special account, that you can read more about here. But briefly, the biggest point in creating bot is that Wikidata Toolkit supports “bot account protocol” out of the box, i.e. it negotiates delays as necessary, depending on the load on WD servers, so you don’t have to worry about this, as a developer.
So, my project was running full steam, I’ve created bot, requested it’s authorization, and, as is prescribed by the procedure, started running my bot on a piece-meal basis, carefully validating all created lexemes and forms. Nothing was predicting a failure…
But then, the thunder in the midst of blue sky! As I was overseeing created lexeme for “esmaspäev” (Monday), I’ve noticed that the forms created looked as:
- esmaspäevi
- esmaspäevisse
- esmaspäevile …
and so on and so on… What is wrong here? Well, it’s just not how you incline “esmaspäev”. Proper genitive would be “esmaspäeva”, with all the rest forms reflecting this too. And at this moment I’ve realized that there’s no way out of destiny. The “syntees” tool I was so relying on for so long, failed me badly. As it turns out, for all it’s seemingly regular nature, Estonian is still not an Esperanto, but a natural language. And it being this way, it’s not so easy to write a fully automated inclination (paradigm building) solution. So, even though it was just one failed paradigm out of probably 70 I’ve uploaded by that time, I realized that I can not and should not, especially as a non-native speaker, rely on this tool, so I had to either abandon the whole thing, OR … to find something else.
As it turns out, by this time I was already corresponding with a person from EKI, who’s suggested me to use EkiLex API instead (which is exactly the same API as Sõnaveeb is using). After applying for, and being granted, a token for API access, I was on track again. This process also has it’s portion of bumps, but finally I was able to settle on something that I could live with. Having created about 50k lexemes with almost 1,7M forms in about a week time span, I finally feel that “my work here is done” :) And that’s an amazing feeling.
And finally: what is the added value for the community at large? First, Wikidata Lexicographical model is supposed to one day (hopefully) become a structured, solid and extensible foundation for Wiktionary. And of course Estonian language will be able to benefit off from it, now that so many lexemes and forms are already defined. But right away, everyone can use Ordia Text-To-Lexemes to parse any Estonian text and immediately observe all potentially tricky forms!
Please, try it yourself! Cheers, and good luck!